A Defense of (Empirical) Neural Tangent Kernels
Danica J. Sutherland(she)
University of British Columbia (UBC) / Alberta Machine Intelligence Institute (Amii)
University of Michigan AI Seminar - March 23, 2023
Slides available at djsutherland.ml/slides/entk-umich
(Swipe or arrow keys to move through slides; for a menu to jump; to show more.)
PDF version
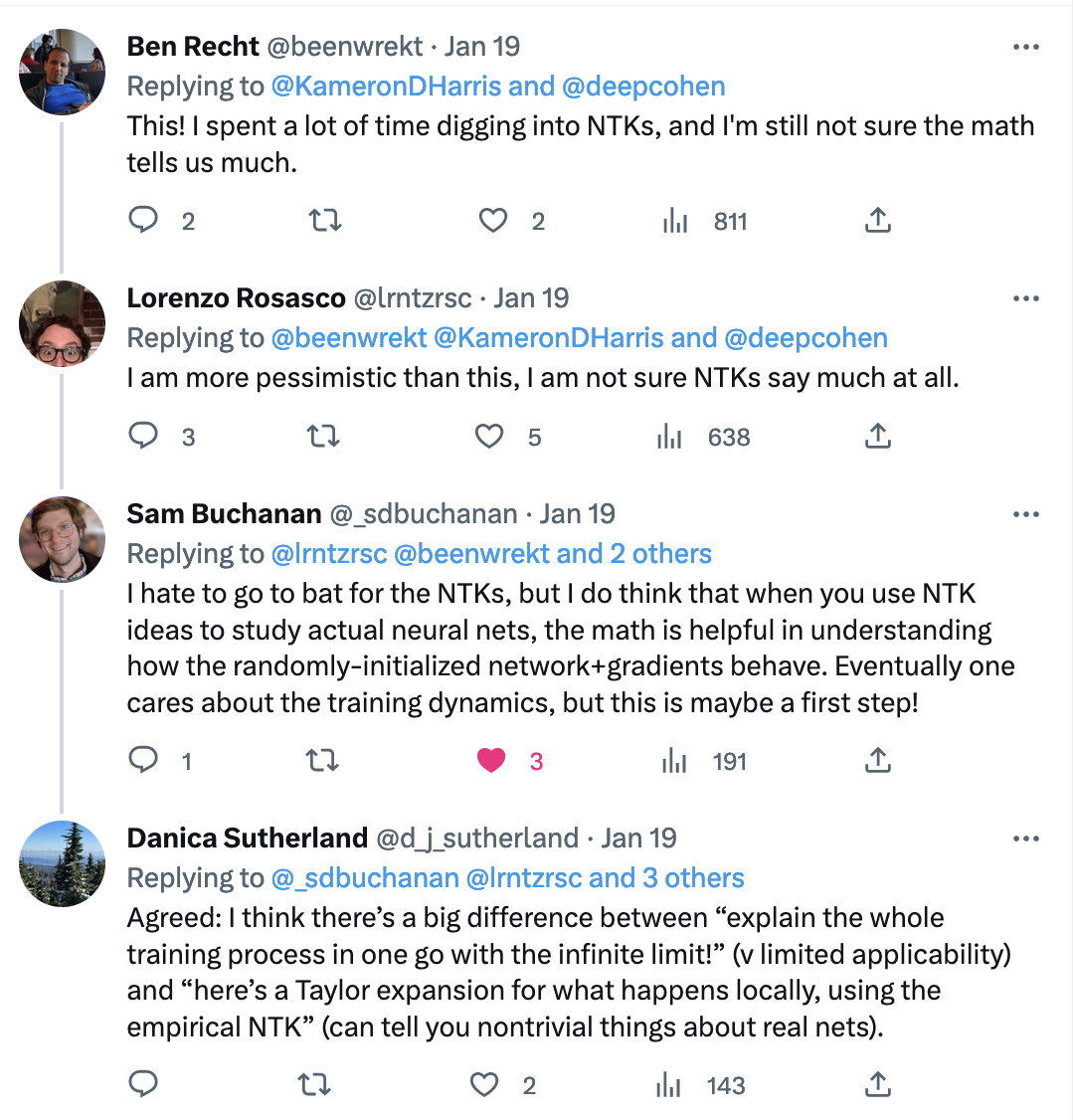
(A lot of) this talk in a tweet:
One path to NTKs(Taylor's version)
- “Learning path” of a model's predictions: for some fixed as params change
- Let's start with “plain” SGD on :
- Defined
- step barely changes prediction if is small
- for square loss, for cross-entropy
- Full-batch GD: “stacking things up”,
- Observation I: If is “wide enough”
with any usual architecture+init* [Yang+Litwin 2021],
is roughly constant through training
- For square loss, : dynamics agree with kernel regression!
- Observation II: As becomes “infinitely wide” with any usual architecture+init* [Yang 2019], , independent of the random
Infinite NTKs are great
- Infinitely-wide neural networks have very simple behaviour!
- No need to worry about bad local minima, optimization complications, …
- Understanding “implicit bias” of wide nets understanding NTK norm of functions
- Can compute exactly for many architectures
- A great kernel for many kernel methods!
- Using in SVMs was then-best overall method across many small-data tasks [Arora+ 2020]
- Good results in
statistical testing [Jia+ 2021],
dataset distillation [Nguyen+ 2021],
clustering for active learning batch queries [Holzmüller+ 2022], …
But (infinite) NTKs aren't “the answer”
- Computational expense:
- Poor scaling for large-data problems: typically memory and to computation
- CIFAR-10 has , : an matrix of float64s is 2 terabytes!
- ILSVRC2012 has , : 11.5 million terabytes (exabytes)
- For deep/complex models (especially CNNs), each pair very slow / memory-intensive
- Poor scaling for large-data problems: typically memory and to computation
- Practical performance:
- Typically performs worse than GD for “non-small-data” tasks (MNIST and up)
- Theoretical limitations:
- NTK “doesn't do feature learning”:
- stays constant
- Internal activations in the networks don't change much [Chizat+ 2019] [Yang/Hu 2021]
- We now know many problems where gradient descent on an NN any kernel method
- Cases where GD error , any kernel is barely better than random [Malach+ 2021]
- NTK “doesn't do feature learning”:
What can we learn from empirical NTKs?
In this talk:
- As a theoretical-ish tool for local understanding:
- Fine-grained explanation for early stopping in knowledge distillation
- How you should fine-tune models
- As a practical tool for approximating “lookahead” in active learning
- Plus: efficiently approximating s for large output dimensions , with guarantees
Better supervisory signal implies better learning
- Classification: target is
- Normally: see , minimize ( is vector of losses for all possible labels)
- Potentially better scheme:
see ,
minimize
- Can reduce variance if , the true conditional probabilities
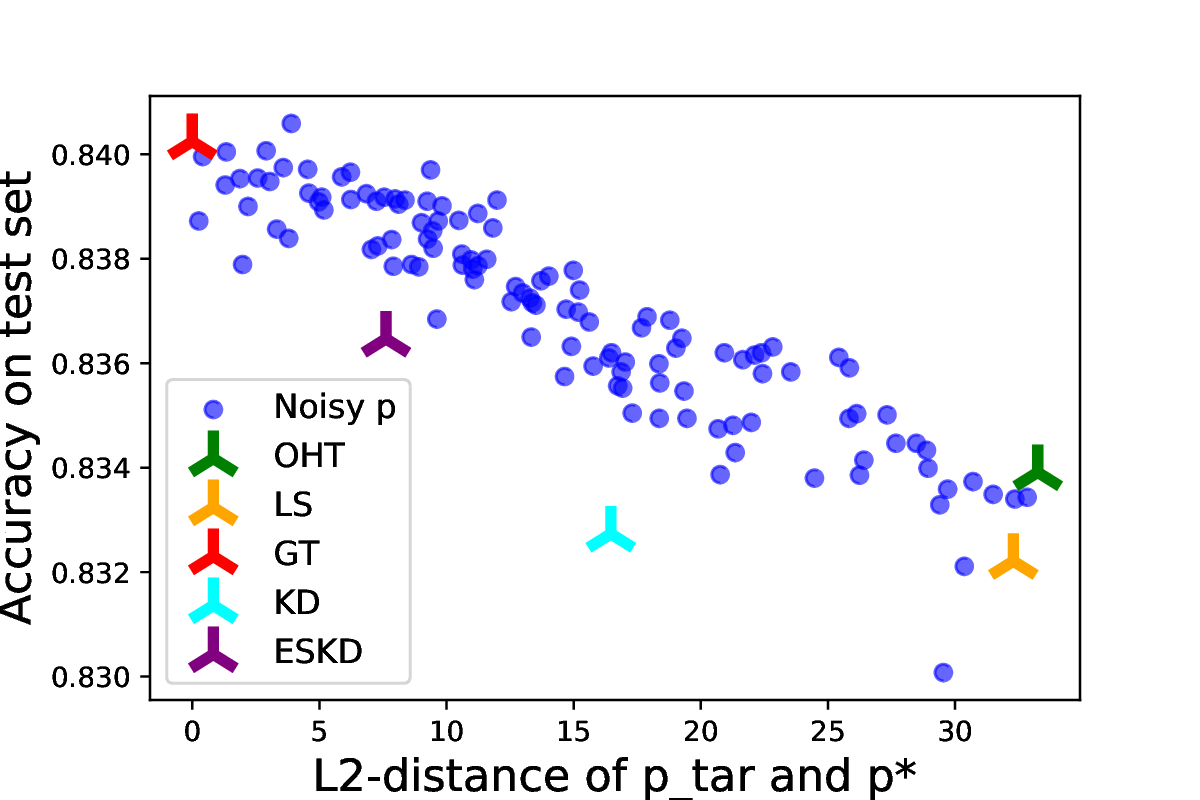
Knowledge distillation
- Process:
- Train a teacher on with standard ERM,
- Train a student on with
- Usually is “smaller” than
- But “self-distillation” (using the same architecture), often outperforms !
- One possible explanation: is closer to than sampled
- But why would that be?
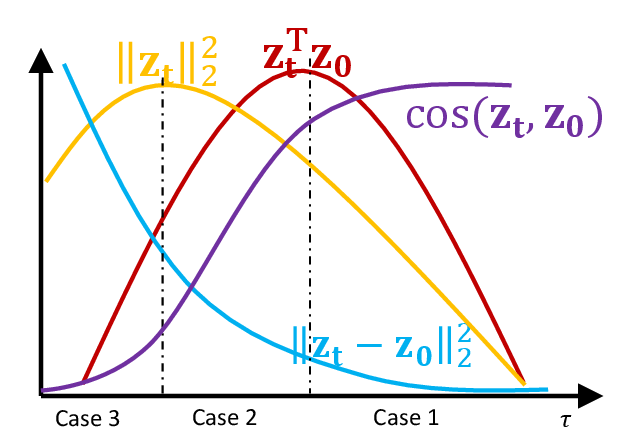
Zig-Zagging behaviour in learning
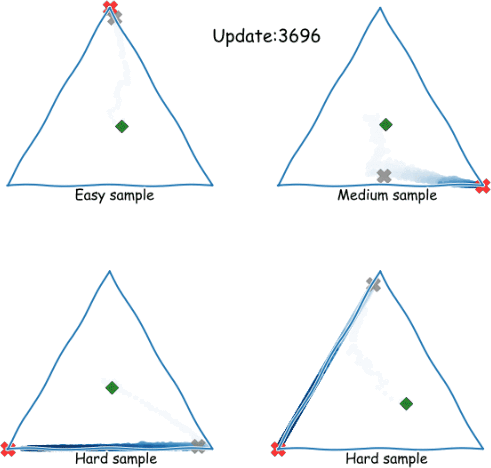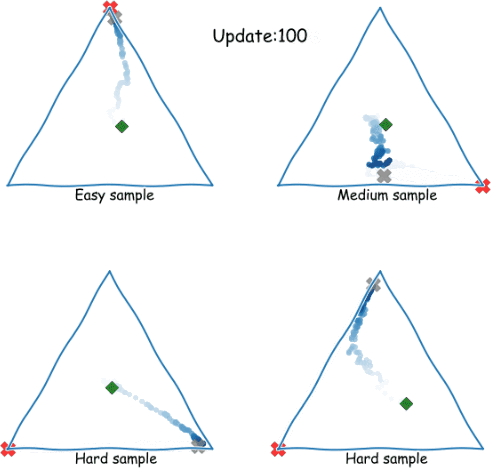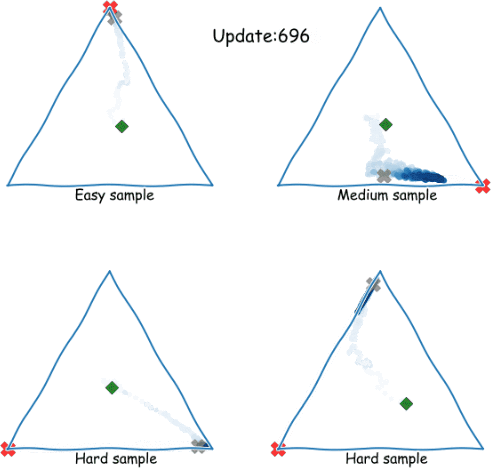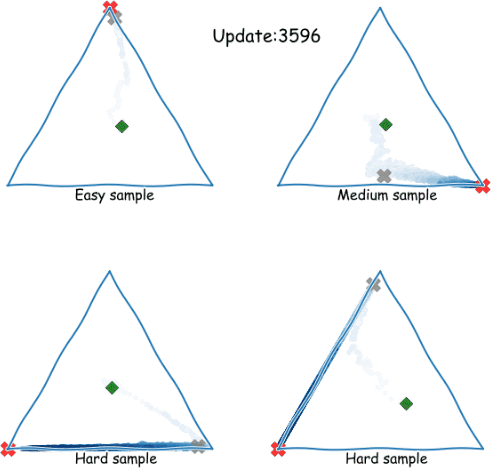
Plots of (three-way) probabilistic predictions: shows , shows
eNTK explains it
- Let ; for cross-entropy loss, one SGD step gives us is the covariance of a
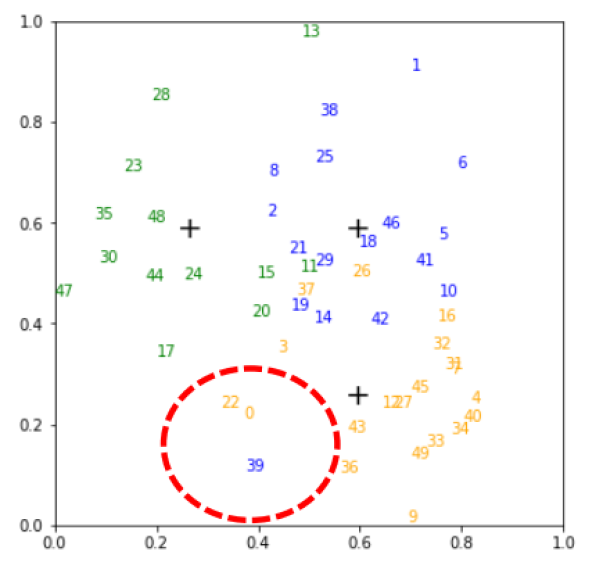
- Improves distillation (esp. with noisy labels) to take moving average of as
What can we learn from empirical NTKs?
In this talk:
- As a theoretical-ish tool for local understanding:
- Fine-grained explanation for early stopping in knowledge distillation
- How you should fine-tune models
- As a practical tool for approximating “lookahead” in active learning
- Plus: efficiently approximating s for large output dimensions , with guarantees
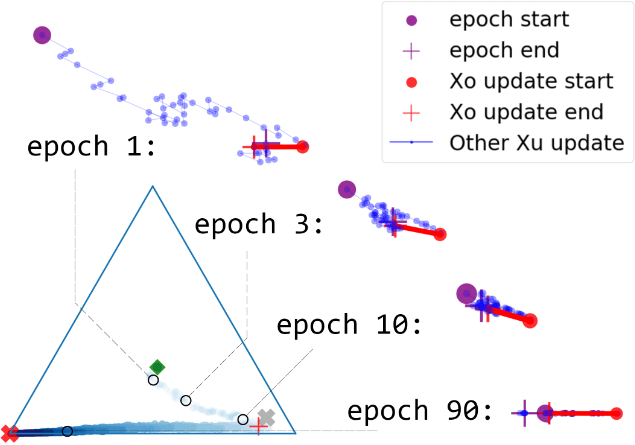
Fine-tuning
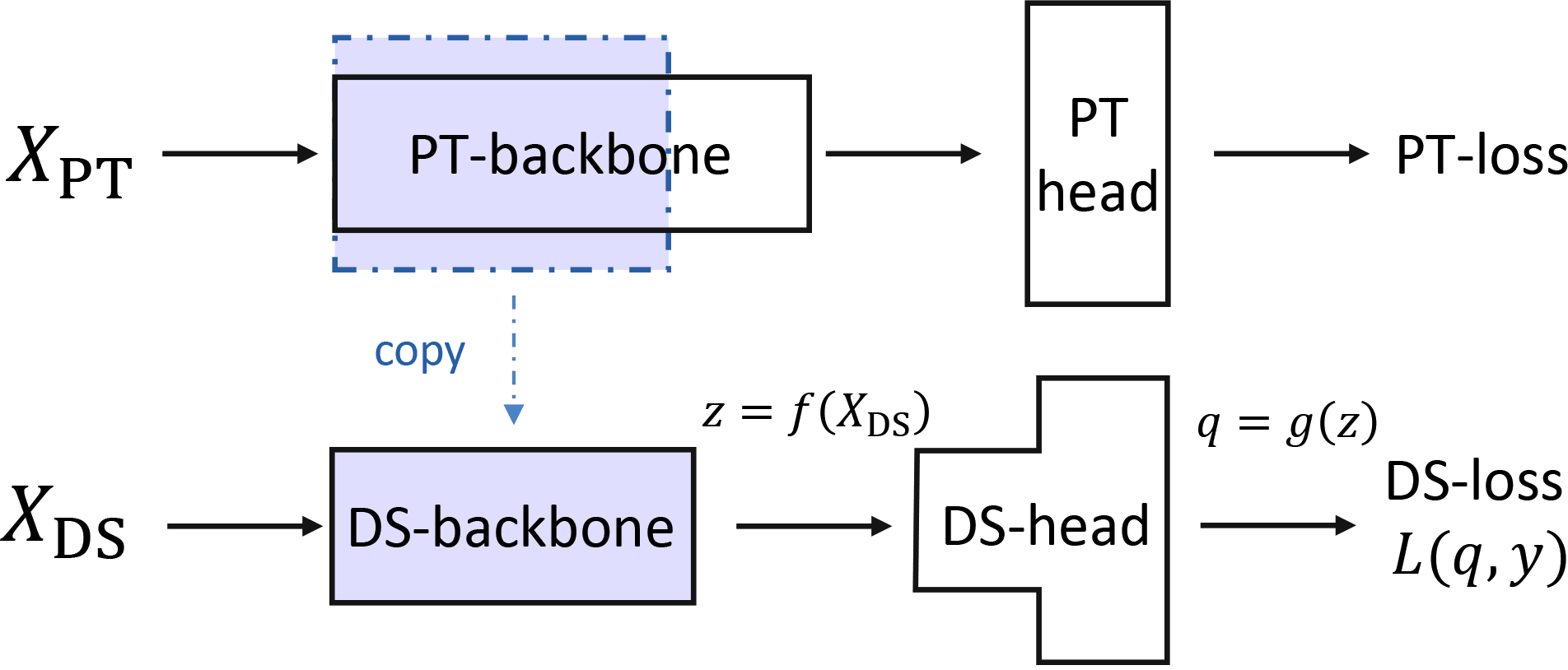
- Pretrain, re-initialize a random head, then adapt to a downstream task.
Two phases:
- Head probing: only update the head
- Fine-tuning: update head and backbone together
- If we only fine-tune: noise from random head might break our features!
- If we head-probe to convergence: might already fit training data and not change features!
How much do we change our features?
- Same kind of decomposition with backbone features , head :
- If initial “energy”, e.g. , is small, features don't change much
- If we didn't do any head probing, “direction” is very random, especially if is rich
- Specializing to simple linear-linear model, can get insights about trends in
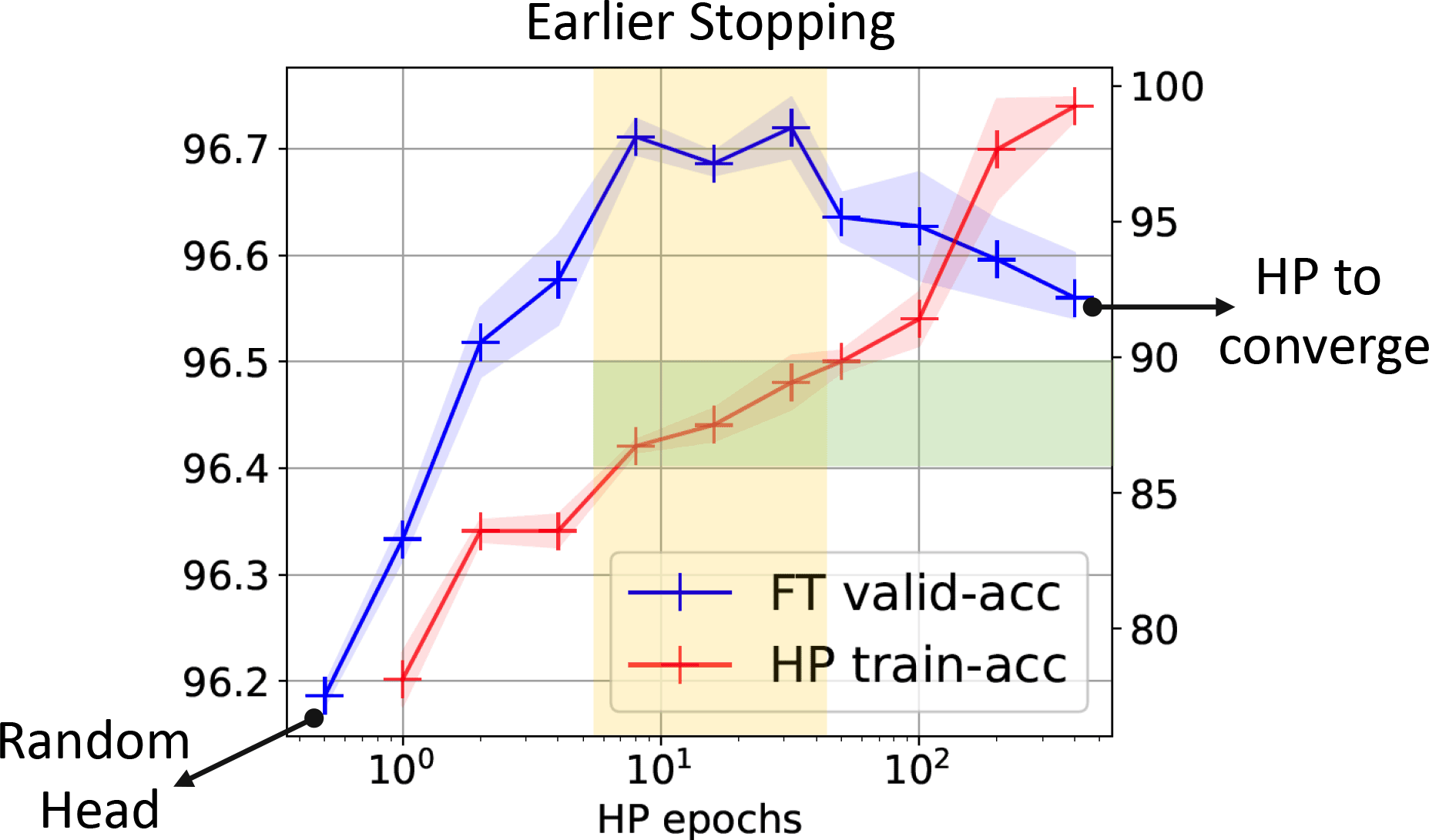
- Recommendations from paper:
- Early stop during head probing (ideally, try multiple lengths for downstream task)
- Label smoothing can help; so can more complex heads, but be careful
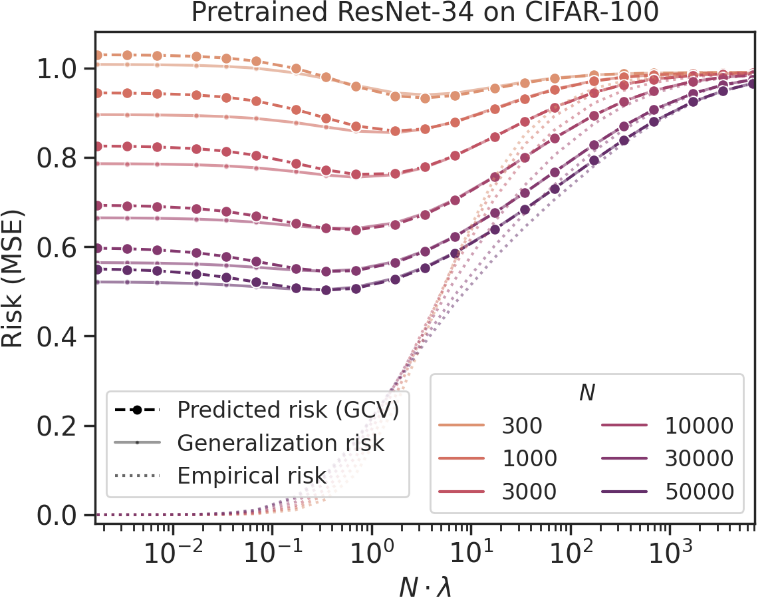
How good will our fine-tuned features be? [Wei/Hu/Steinhardt 2022]
- With random head (no head probing),
generalized cross-validation on eNTK model gives excellent estimate of downstream loss

What can we learn from empirical NTKs?
In this talk:
- As a theoretical-ish tool for local understanding:
- Fine-grained explanation for early stopping in knowledge distillation
- How you should fine-tune models
- As a practical tool for approximating “lookahead” in active learning
- Plus: efficiently approximating s for large output dimensions , with guarantees
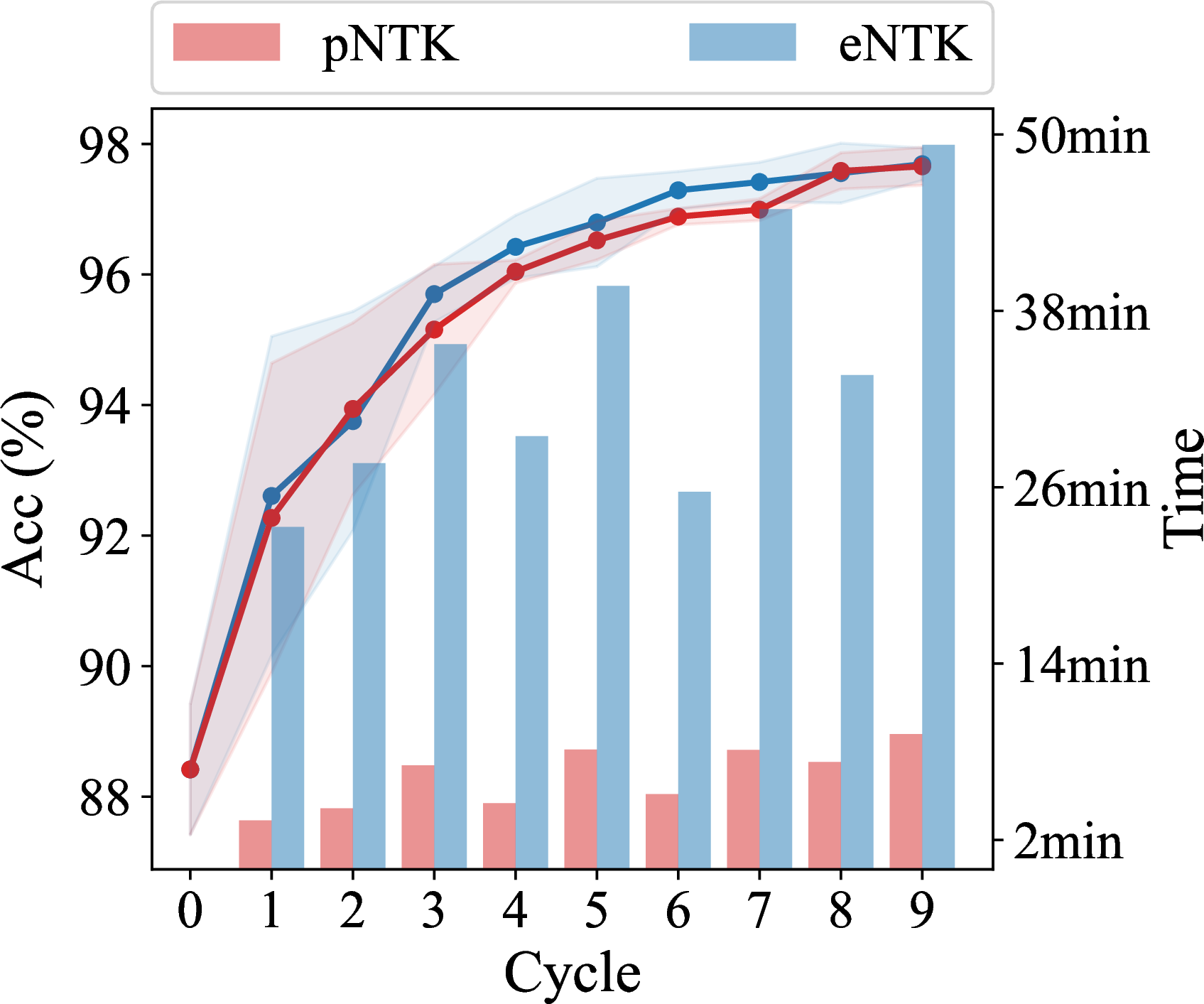
Pool-based active learning
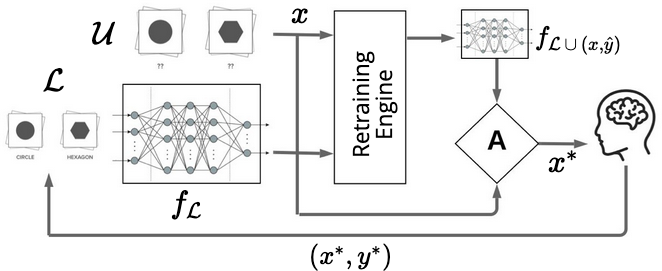
- Pool of unlabeled data available; ask for annotations of the “most informative” points
- Kinds of acquisition functions used for deep active learning:
- Uncertainty-based: maximum entropy, BALD
- Representation-based: BADGE, LL4AL
- Another kind used for simpler models: lookahead criteria
- “How much would my model change if I saw with label ?”
- Too expensive for deep learning…unless you use a local approximation to retraining
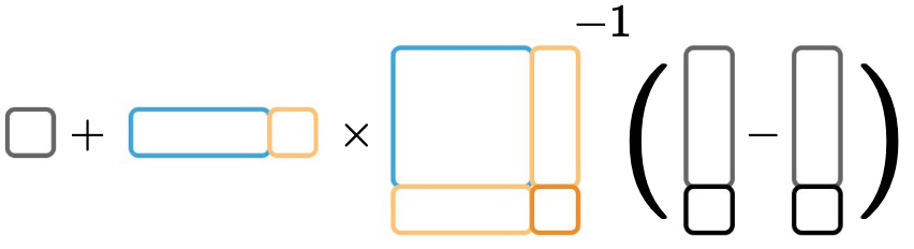
Approximate retraining with local linearization
- Given trained on labeled data , approximate with local linearization
- Rank-one updates for efficient computation: schema
![]()
- Rank-one updates for efficient computation: schema
- We prove this is exact for infinitely wide networks
- agrees with direct
- Local approximation with eNTK “should” work much more broadly than “NTK regime”
Much faster than SGD
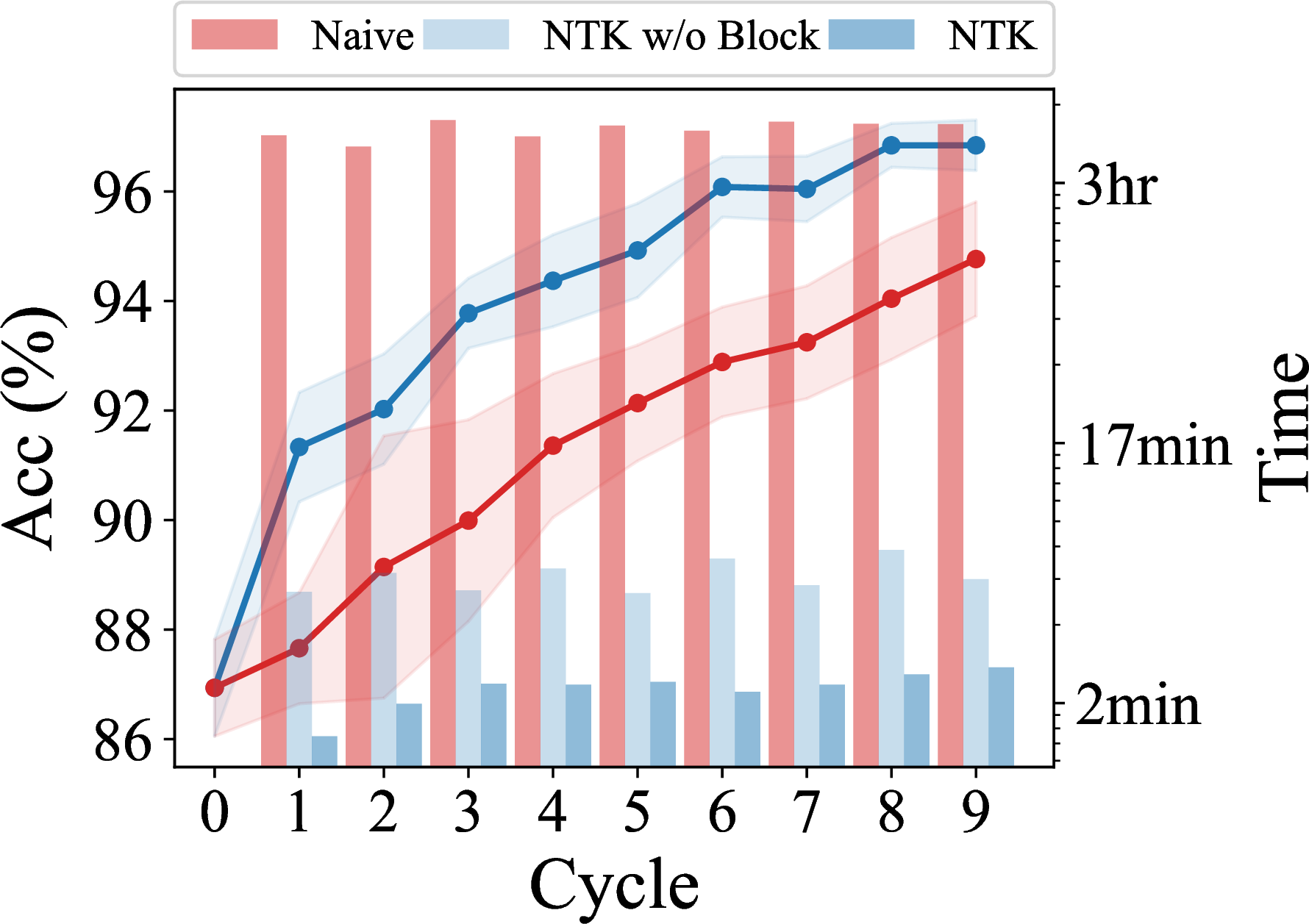
Much more effective than infinite NTK and one-step SGD
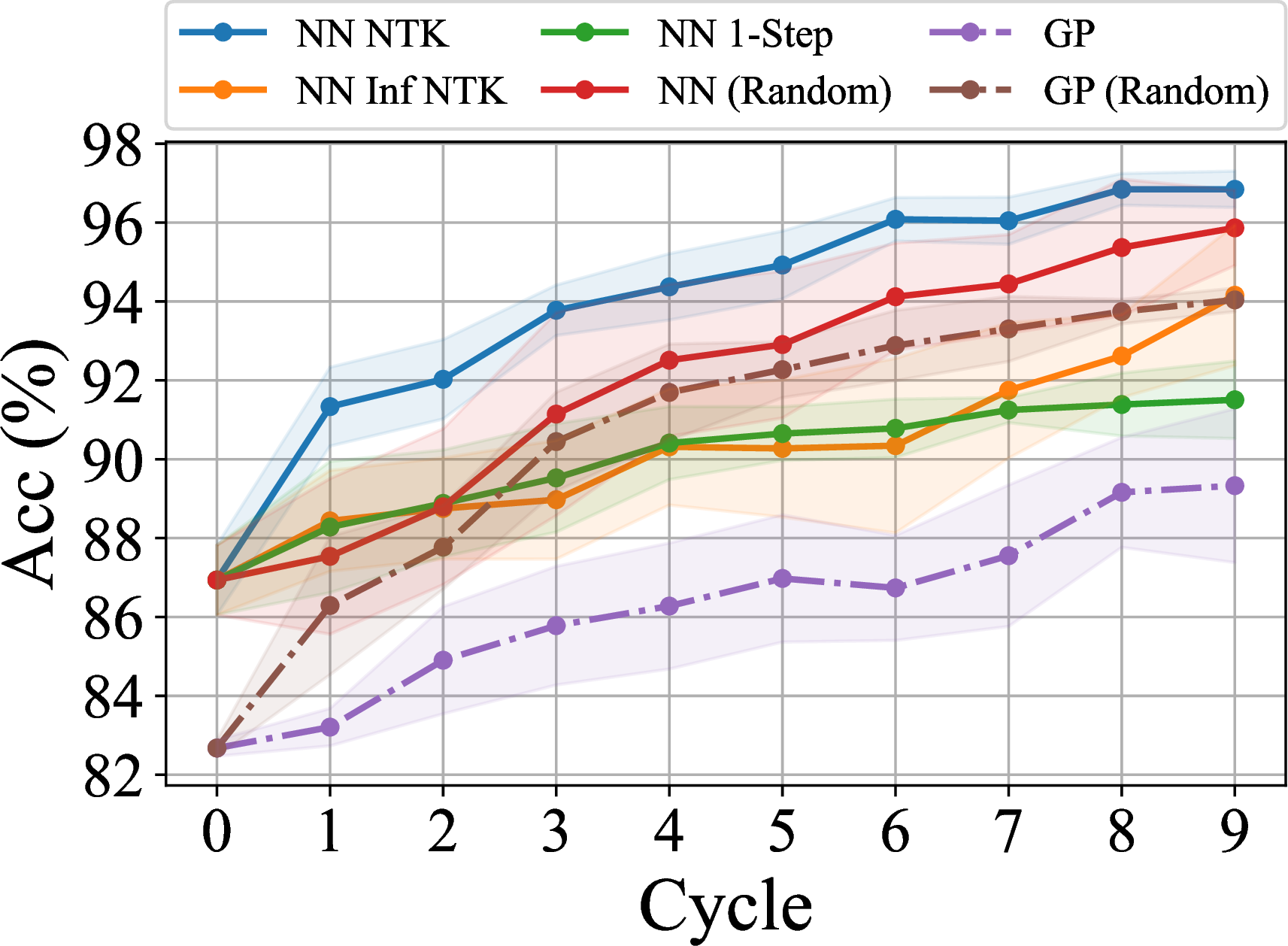
Matches/beats state of the art
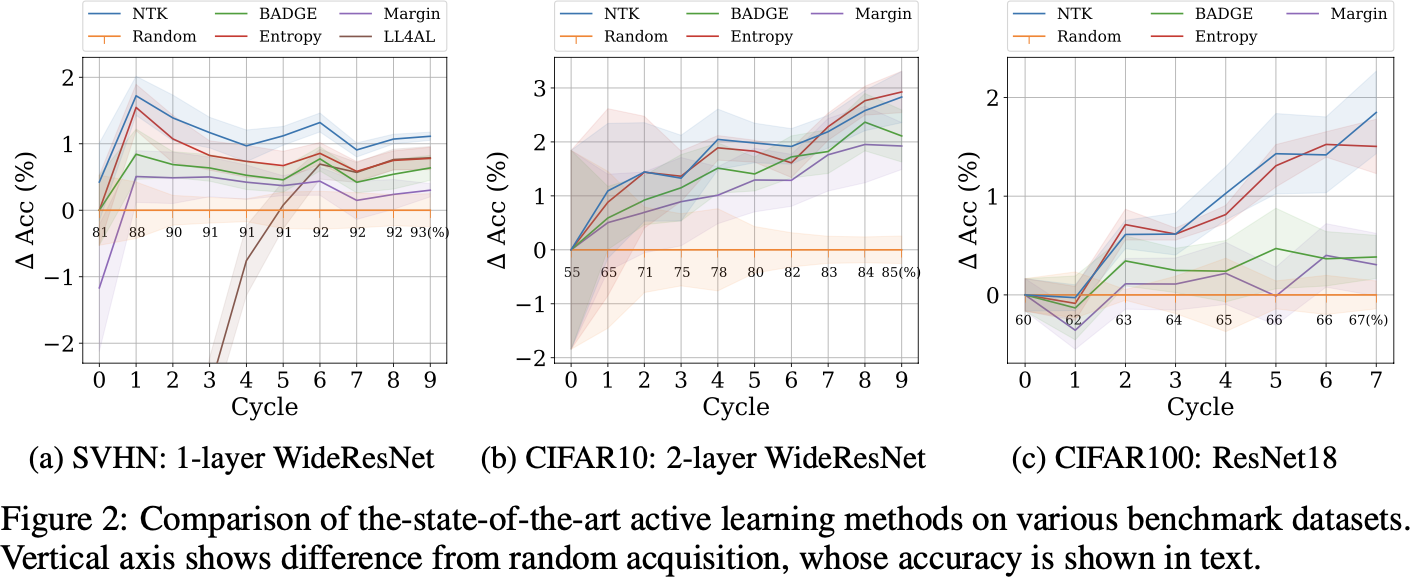
Downside: usually more computationally expensive (especially memory)
Enables new interaction modes
- “Sequential” querying: incorporate true new labels one-at-a-time instead of batch
- Only update occasionally
- Makes sense when labels cost $ but are fast; other deep AL methods need to retrain
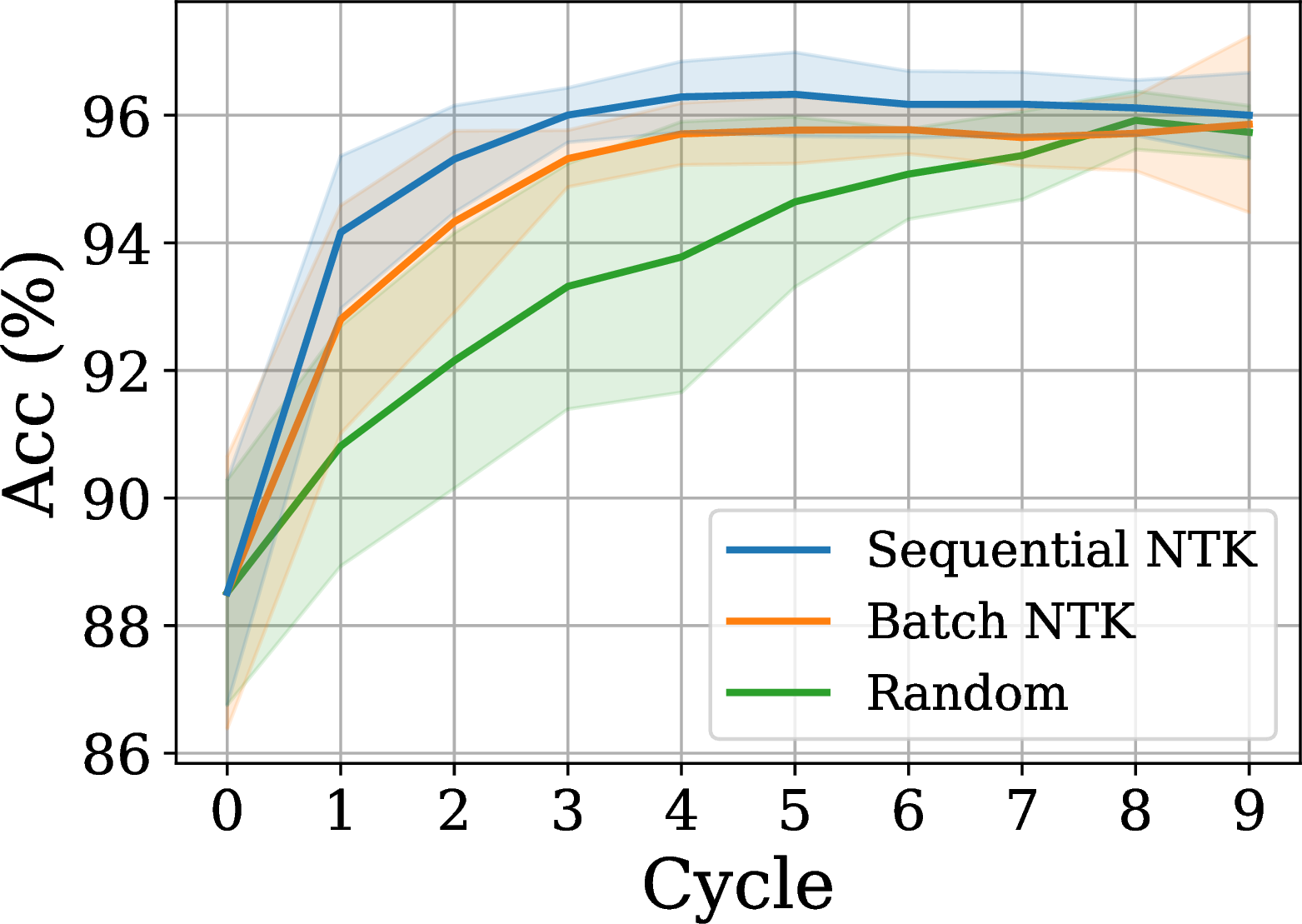
What can we learn from empirical NTKs?
In this talk:
- As a theoretical-ish tool for local understanding:
- Fine-grained explanation for early stopping in knowledge distillation
- How you should fine-tune models
- As a practical tool for approximating “lookahead” in active learning
- Plus: efficiently approximating s for large output dimensions , with guarantees
Approximating empirical NTKs
- I hid something from you on active learning (and Wei/Hu/Steinhardt fine-tuning) results…
- With classes, – potentially very big
- But actually, we know that is diagonal for most architectures
- Let . (no !)
- Can also use “sum of logits” instead of just “first logit”
- Lots of work (including above) has used instead of
- Often without saying anything; sometimes doesn't seem like they know they're doing it
- Can we justify this more rigorously?
pNTK motivation
- Say , , and has rows with iid entries
- If , then and have same distribution
- We want to bound difference
- Want and to be close, and small, for random and fixed
- Using Hanson-Wright:
- Fully-connected ReLU nets at init., fan-in mode: numerator , denom
pNTK's Frobenius error
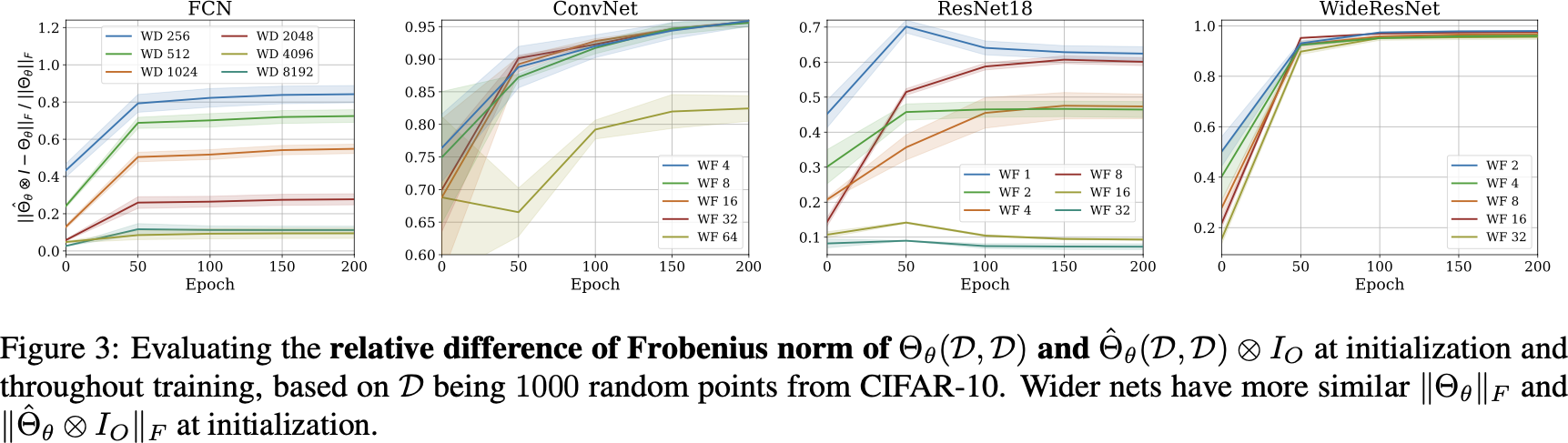
Same kind of theorem / empirical results for largest eigenvalue,
and empirical results for , condition number
Kernel regression with pNTK
- Reshape things to handle prediction appropriately:
- We have again
- If we add regularization, need to “scale” between the two
Kernel regression with pNTK
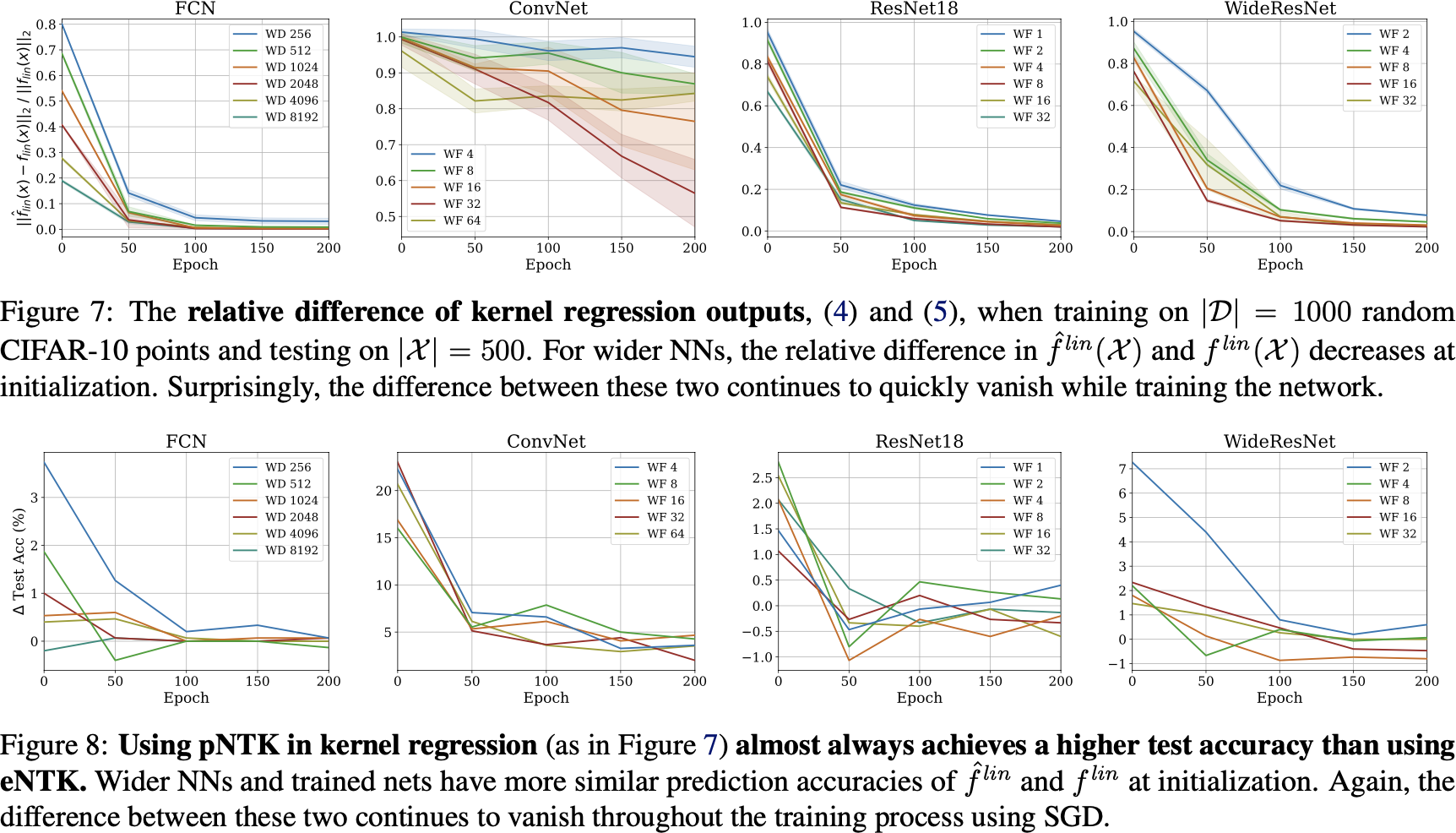
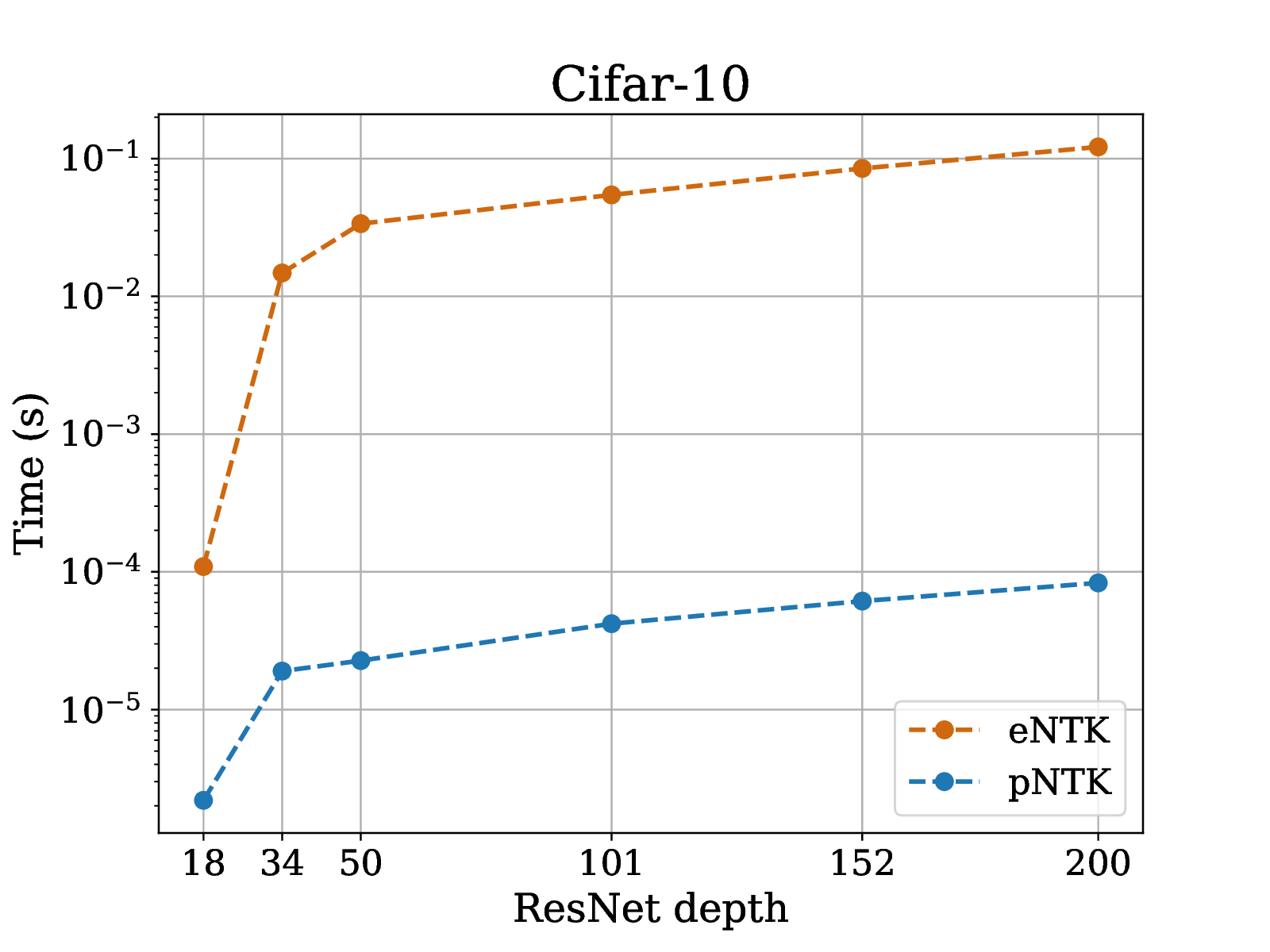
pNTK speed-up
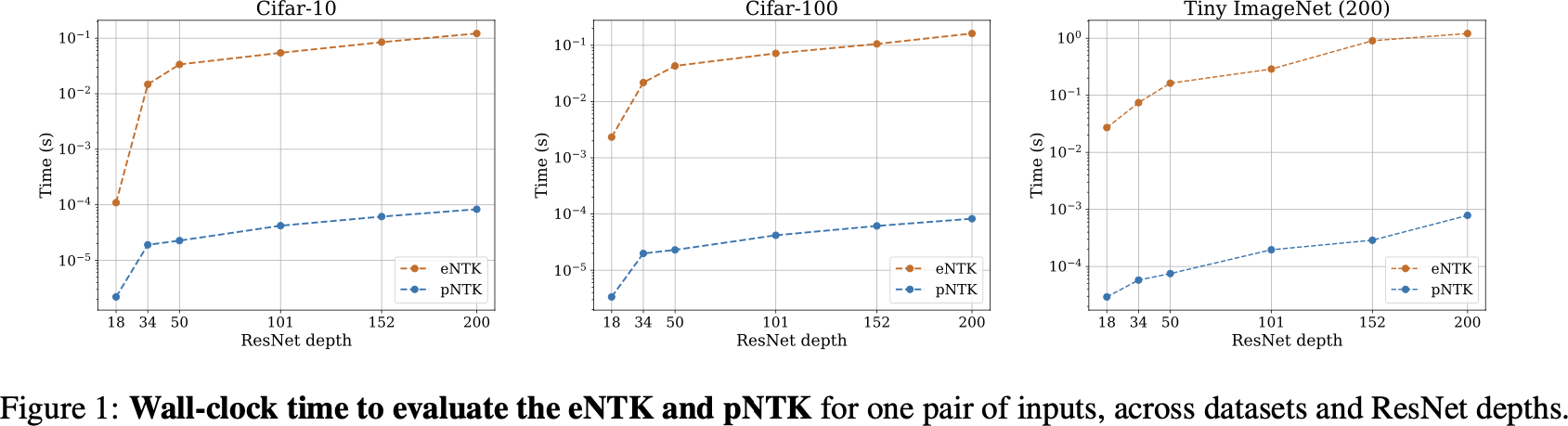
pNTK speed-up on active learning task
pNTK for full CIFAR-10 regression
- on CIFAR-10: 1.8 terabytes of memory
- on CIFAR-10: 18 gigabytes of memory
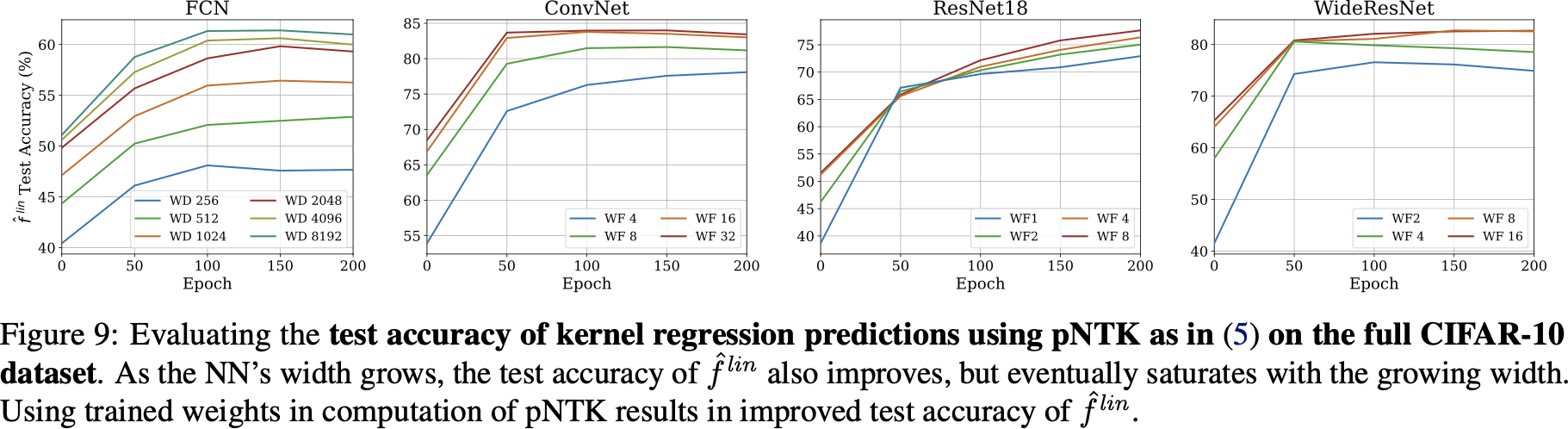
- Worse than infinite NTK for FCN/ConvNet (where they can be computed, if you try hard)
- Way worse than SGD
Recap
eNTK is a good tool for intuitive understanding of the learning process
eNTK is practically very effective at “lookahead” for active learning
You should probably use pNTK instead of eNTK for high-dim output problems: