Can Uniform Convergence
Explain Interpolation Learning?
Lijia Zhou
U Chicago
![]()
Nati Srebro
TTI-Chicago
![]()
Penn State Statistics Seminar, October 8 2020
(Swipe or arrow keys to move through slides; for a menu to jump; to show more.)
Supervised learning
- Given i.i.d. samples
- features/covariates , labels/targets
- Want such that for new samples from :
- e.g. squared loss:
- Standard approaches based on empirical risk minimization:
Statistical learning theory
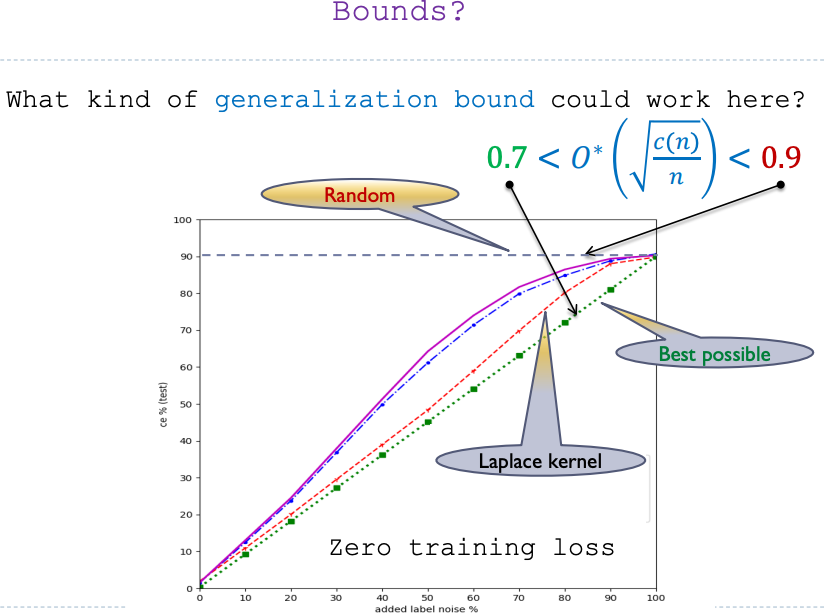
We have lots of bounds like:
with probability ,
could be from VC dimension, covering number, RKHS norm, Rademacher complexity, fat-shattering dimension, …
Then for large , , so
Interpolation learning
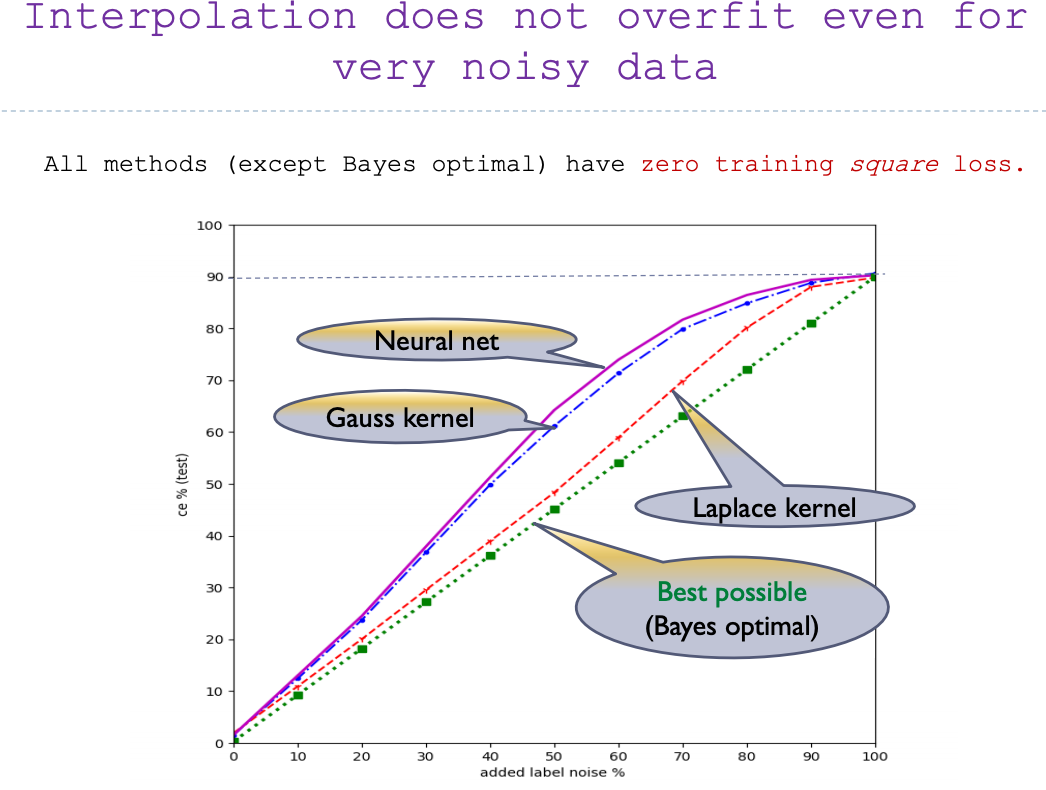
Classical wisdom: “a model with zero training error is overfit to the training data and will typically generalize poorly”
(when )![]()
We'll call a model with an interpolating predictor
![]()
![]()
Added label noise on MNIST (%)
Belkin/Ma/Mandal, ICML 2018![]()
![]()
![]()
![]()
A more specific version of the question
We're only going to worry about consistency:
…in a non-realizable setting:
Is it possible to show consistency of an interpolator with
This requires tight constants!
Our testbed problem
| “signal”, | “junk”, |
| | |
| | |
|
controls scale of junk:
Linear regression:
Min-norm interpolator:
Consistency of
As , approaches ridge regression on the signal:
for almost all
If , is consistent:
is consistent when fixed, , .
Could we have shown that with uniform convergence?
No uniform convergence on norm balls
Theorem:
If ,
Proof idea:
A more refined uniform convergence analysis?
is no good. Maybe ?
![]()
For each
,
let
,
a
natural consistent interpolator,
and
.
Then, almost surely,
([Negrea/Dziugaite/Roy, ICML 2020] had a very similar result for )
Natural interpolators: doesn't change if flips to . Examples:
,
,
,
with each convex,
Proof shows that for most ,
there's a typical predictor (in )
that's good on most inputs (),
but very bad on specifically ()
So, what are we left with?
One-sided uniform convergence?
We don't really care about small , big ….
Could we bound instead of ?
- Existing uniform convergence proofs are “really” about [Nagarajan/Kolter, NeurIPS 2019]
- Strongly expect still for norm balls in our testbed
- instead of
- Not possible to show is big for all
- If consistent and , use
A broader view of uniform convergence
So far, used
But we only care about interpolators. How about
Is this “uniform convergence”?
It's the standard notion for realizable () analyses…
Are there analyses like this for ?
Optimistic rates
Applying [Srebro/Sridharan/Tewari 2010]:
for all ,
: high-prob bound on
if , , But if we suppose , would get a novel prediction:
Main result
Theorem: If ,
- Confirms speculation based on assumption
- Shows consistency with uniform convergence (of interpolators)
- New result for error of not-quite-minimal-norm interpolators
- Norm is asympotically consistent
- Norm is at worst
What does
look like?
is the plane
Intersection of -ball with -hyperplane:
-ball centered at
Can write as
where is any interpolator,
is basis for
Decomposition via strong duality
Can change variables in to
Quadratic program, one quadratic constraint: strong duality
Exactly equivalent to problem in one scalar variable:
Can analyze this for different choices of …
The minimal-risk interpolator
In Gaussian least squares generally, have that
so is consistent iff .
Very useful for lower bounds! [Muthukumar+ JSAIT 2020]
Restricted eigenvalue under interpolation
Roughly, “how much” of is “missed” by
Consistency up to
Analyzing dual with
,
get without
any distributional assumptions that
(amount of missed energy)
(available norm)
If
consistent, everything smaller-norm also consistent iff
term
In our setting:
is consistent,
Plugging in:
Error up to
Analyzing dual with for , , get in general: if is consistent
In our setting:
is consistent, because
Plugging in:
…and we're done!
On Uniform Convergence and Low-Norm Interpolation Learning
Zhou, Sutherland, and Srebro
NeurIPS 2020
- “Regular” uniform convergence can't explain consistency of
- Uniform convergence over norm ball can't show any learning
- An “interpolating” uniform convergence bound does
- Shows low norm is sufficient for interpolation learning here
- Predicts exact worst-case error as norm grows
- Optimistic/interpolating rates might be able to explain interpolation learning more broadly
- Need to get the constants on leading terms exactly right!
- Analyzing generalization gap via duality may be broadly applicable
- Can always get upper bounds via weak duality